RSS (Really Simple Syndication) ir standartizēts formāts, ko izmanto tiešsaistes izdevēji sindicēt to saturu citām tīmekļa vietnēm un pakalpojumiem. An RSS dokuments, pazīstams arī kā a barību, ir XML dokuments saturu, ko izdevējs vēlas izplatīt.
RSS plūsmas ir pieejamas gandrīz visās tiešsaistes ziņu vietnēs un emuāros, lai lasītāji varētu to lasīt palikt atjaunināti ar to saturu. Tās var atrast arī ar tekstu nesaistītas tīmekļa vietnes piemēram, YouTube, kur var izmantot YouTube kanāla plūsmu informēti par jaunākajiem videoklipiem.
Tiek izsauktas programmas, kas piekļūst šīm plūsmām un lasa un parāda to saturu RSS lasītāji. JavaScript var izveidot vienkāršu RSS lasītāju programmu. Šajā apmācībā mēs redzēsim, kā to izdarīt.
RSS plūsmas struktūra
RSS plūsma ir saknes elements sauc , līdzīgs tags atrodams HTML dokumentos. Iekšpusē tag, ir elements, piemēram, HTML, tas ir ietver daudzus apakšelementus satur izplatīto tīmekļa vietnes saturu.
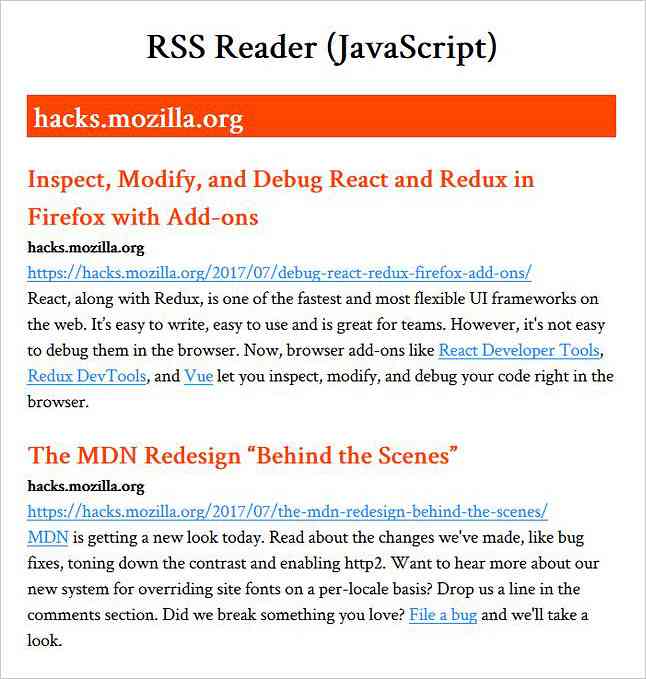
Barība parasti nes dažus Pamatinformācija piemēram, nosaukums, URL un tīmekļa vietnes un atsevišķas atjauninātas ziņas, raksti vai cits saturs tīmekļa vietnes. Šī informācija ir atrodama </code>, <code><link></code>, un <code><description></code> elementiem.</p> <p>Kad tās ir <strong>tieši klāt <code><channel></code></strong>, viņiem ir tīmekļa vietnes nosaukums, URL un apraksts. Kad viņi ir <strong>klāt <code><item></code></strong> to <strong>glabā informāciju par atjauninātajām ziņām</strong>, tie ir tādi paši dati kā iepriekš, bet katras atsevišķās informācijas saturs <code><item></code> pārstāvēt.</p> <p>Ir arī daži <strong>izvēles elementi</strong> kas var būt RSS plūsmā, sniedzot papildu informāciju, piemēram, attēlus vai autortiesības uz izplatīto saturu. Par tiem varat uzzināt šajā <strong>RSS 2.0 specifikācija</strong> pie cyber.harvard.edu.</p> <p>Šeit ir paraugs, kā <strong>Mājas lapas RSS plūsma</strong> varētu izskatīties šādi:</p> <pre name="code"> <rss version="2.0"> <channel> <title>Hongkiat https://www.hongkiat.com/ Dizaina padomi, apmācība un iedvesmaslv-mumsVizualizējiet jebkuru CSS stilu ar CSS statistikuKādreiz bija jautājums, cik CSS noteikumi ir stilu lapā? Vai esat kādreiz gribējis redzēt… 18/05/2017 https://www.hongkiat.com/blog/css-stylesheet-with-css-stats/ Amazon Echo Show - jaunākais Alexa darbināmais Smart DeviceAmazon nav svešs priekšstats par viedām mājas sistēmām ar iebūvētu digitālo palīgu. Galu galā,… 17/05/2017 https://www.hongkiat.com/blog/alexa-device-amazon-echo-show/
Ievades plūsma
Mums vajag ielādējiet plūsmu izmantojot mūsu RSS lasītāja programmu. Tīmekļa vietnē var būt RSS plūsmas URL atrodas iekšpusē tagu, izmantojot application / rss + xml veids. Piemēram, Hongkiat.com atradīsiet šādu RSS plūsmas saiti.
Pirmkārt, pieņemsim, kā to izdarīt iegūt vietnes URL izmantojot JavaScript.
The ielādēt () metode ir globāla metode asinhroni ielādē resursu. Tas aizņem resursa URL kā argumentu (vietnes URL mūsu kodā). Tā atgriež a Solījums objektu, tāpēc, kad metode veiksmīgi ielādē vietni (t.i. Solījums ir izpildīta), pirmā funkcija iekšpusē tad () paziņojums, apgalvojums apstrādā ielādēto atbildi (res iepriekš minētajā kodā).
Tad ir saņemta atbilde pilnībā izlasīts teksta virknē izmantojot teksts () metodi. Šis teksts ir Mūsu ielādētās vietnes HTML teksts. Tāpat kā ielādēt (), teksts () arī atgriež a Solījums objektu. Tātad, kad tas veiksmīgi izveido atbildes tekstu no atbildes plūsmas, tad () apstrādās šo atbildes tekstu (htmlText iepriekš minētajā kodā).
Kad būs pieejams HTML tīmekļa vietnes teksts, mēs izmantojam DOMParser API uz analizēt to DOM dokumentā. DOMParser analizē XML / HTML teksta virkni DOM dokumentā. Tās metode, parseFromString (), ņem divi argumenti: izdomāts teksts un satura veids.
Tad no izveidotā DOM dokumenta mēs Atrodi href attiecīgās vērtības tag izmantojot querySelector () metodi, lai iegūtu plūsmas URL.
Plūsmas analīze un attēlošana
Kad būsim saņēmuši vietnes vietnes URL, mums ir nepieciešams ielādējiet un lasiet RSS dokumentu atrasts šajā URL.
Tāpat kā mēs ielādējām un analizējām tīmekļa vietni, tagad mēs iegūt un analizēt XML plūsmu DOM dokumentā. Lai to panāktu, mēs izmantojam 'text / xml' satura veids parseFromString () metodi.
Parsētā dokumentā mēs atlasiet visu elementiem izmantojot querySelectorAll metode un cilpa caur katru.